
Sample data submission illustrating requested format. The oberver name format is: last name, comma, first name and observer code in parentheses.
This web page describes how to prepare a data file for submission to the
AXA. Since I am now writing the program that will process data on Caltech's
IPAC computer (for the NStED archive), you can assume that the following
format requirements will be very similar to what Caltech will require. Whereas
I have been very willing to modify the format of data files submitted to
the AXA (almost all data files had to be modified), Caltech's computer will
automatically reject any files that fail to conform to the required format.
I therefore suggest that anyone currently submitting to the AXA consider
reviewing how their data files for submission are formatted.
Image Processing Considerations
I can think of three types of photometry leading to a data file that can
be used for submission to the AXA:
1) comp/chk,
2) ensemble photometry, and
3) artificial star photometry.
The first one, "comp/chk", makes use of one star for reference (called
"comp" for historical reasons) and one or more check stars. The "comp" star
can be assigned any magnitude (since a zero offset is irrelevant for exoplanet
light curves). This is the worst of the three procedures because SNR is degraded
(by root-2) and you have no assurance that the "comp" star isn't a variable.
I've seen several stars near an exoplanet star show as variable, and in one
case a nearby star was an eclipsing binary (HD 149026). AAVSO observers are
likely to use this procedure because it's OK for variable star observing.
The second one is better, "ensemble photometry", because it at least uses
many stars for reference. (The reference stars can be assigned any old magnitudes,
such as zero for them all, since zero shifts are irrelevant for exoplanet
light curves.) The root-2 SNR degradation essentially disappears when several
stars are used for reference. If at least 4 stars are used for reference
then their average scintillation will be no more than half the scintillation
level of the target star. (I typically use about 20 reference stars.) The
main drawback of this procedure is that one of the stars may be variable,
but at least it's variability is averaged down by the others that are constant.
The third one, "artificial star photometry", is the best, but it also
requires the most work. I've never heard of AAVSO observers using this procedure,
but I recommend it for all photometry tasks. It involves placing an artificial
star (Gaussian shaped) in the upper-left corner of each image (after caclibration
and star alignment). The program that does this is a plug-in for MaxIm DL
(and maybbe other image analysis programs) written by Ajai Sehgal (downloadable
from one of my web sites: http://brucegary.net/book_EOA/xls.htm.
When the photometry tool is invoked the artificial star is used as reference
and all other nearby stars are called "chk." The artificial star's magnitude
can be anything you want (I always use zero). When the resulting CSV-file
is imported to a spreadsheet (such as my LCas.xls) the user may inspect the
behavior of all "chk" stars and with a simple toggle of a switch in the spreadsheet
the user may specify the star for use as a reference star or not. The effect
of including or excluding each star is immediately seen in the exoplanet
light curve. The effect of including/excluding a "chk" star for use as reference
can also be seen in the RMS of the target star magnitudes. When a sub-set
of the "chk" stars have been chosen there is a 3-column region that can be
copied to a text file containing the following: JD, dMag, ExtraLosses. An
alternative section of this spreadsheet includes a 4th column: dMag SE.
All three of the above procedures lead to a text file with at least two
columns: JD and dMag. The dMag values can have any offset from truth, since
zero shifts are irrelevant in creating exoplanet transit light curves. The
AXA (and Caltech) will process only the first two columns to create a LC,
and they must be JD and dMag; other columns may be present but they will
be ignored. There's one exception to the 2-column rule: a third column will
be processed as "extra losses" if there's a header line stating "Loss
column : Y". An "extra losses" column can be produced when an
artificial star is used for reference (with MaxIm DL, for example) or
if an image processing program is used that records fluxes instead of magnitudes
(for all stars). To calculate extra losses requires that a spreadsheet
program be used to analyze the sum of fluxes for all stars (not including
the exoplanet star). Very few observers include this third "extra losses"
column, so if you're not planning on calculating it you may ignore this
paragraph.
The following is an example of the desired submission format. The program that reads an observer's text file is flexible, and can recognize a header line in any location within the header. Upper and lower case are not important.
Sample data submission
illustrating requested format. The oberver name format is:
last name, comma, first name and observer code in parentheses.
StartDate has format: YYYYMMDD, and please use UT for designating
a start date. This can be confusing for observers in the USA.
Object is the exoplanet name , which can be in almost any format. For example, all of the following are acceptable: GJ 436, GJ436, GJ436b, gj436, gj436b, etc.
Observer name format should be: Last name, Comma, First name, open parenthesis, 3-letter observer code, close parenthesis. The observer code in parentheses is optional, but I recommend using it.
Sometimes it may be difficult to decide whose name to use for "observer"
when more than one person is involved with observing, data analysis or data
file submission. An observation could be a "club project," or a "school
project," in which an experienced observer tutors others in performing these
tasks. If all tasks are closely supervised then the experienced person's
name should be used in the "observer" header line. But if the tutor's principal
role is to provide advice and answer questions, or if the tutor's role is
mostly limited to submitting the data file to the AXA (when proficiency in
English is an issue), then one of the actual observers should be selected
for the "observer" line. It is OK to use two observer names, but I don't want
more than two. When two observer names are used please try to assign the
first one based on who had the greatest responsibility for producing or processing
the data (e.g., I frown on alphabetical listings). I recognize that sometimes
responsibilities can be shared in an enduring way, as when one person does
the observing while another does the image processing and data analysis.
Both tasks are important, and this could be a situation for using two names
in the "observer" line. The guiding principle in selecting the first (or
only) observer name is "Who assumes the greatest responsibility for the quality
of the final data product?" I realize that this can be a difficult question
to answer, especially with a student, but hopefully the "subjective phase"
for who's most responsible is likely to be brief. The e-mail doesn't have
to belong to any of the observers; it can be anyone who can act as a contact
for questions related to the observations that may arise later. Here's an
example of a two-observer submission:
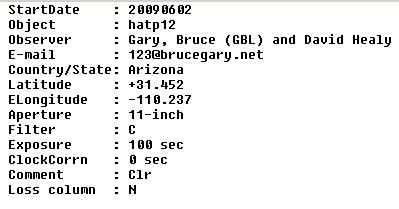 Notice that when there are two observers the second name is simply first
and last (without any observer code in parentheses).
Notice that when there are two observers the second name is simply first
and last (without any observer code in parentheses).
E-mail address for the observer is optional, but again, I highly
recommend including it. If your data is used by a professional astronomer
it is a good idea to include your e-mail address to increase the probability
that the professional will contact you before publishing results that are
partially based on your data.
Location should show the country where the observing site is located,
except for United States locations where the state should be used. You may
also use a city name, such as "Madrid", when it is obvious what location
is being indicated (e.g., "Madrid" means Madrid, Spain, not Madrid, Missouri,
USA). Use your judgement in deciding whether to specify "country" or "city"
or "state." If a user of the data is uncertain about the location they can
consult the site coordinates.
Latitude should be NORTH latitude, in degrees, e.g., +39.17. The
word "Latitude:" must be included in its entirety
(case doesn't matter), followed by the ":" symbol.
ELongitude is used instead of "Longitude" because some observers
may casually use the wrong sign (e.g., all USA is east longitudes, or
negative values for ELongitude).
Aperture can be metric, but I prefer inches for amateur telescopes
(which is easier to understand: 14-inch or 0.35-meter). If only a number
is given it will be assumed to be inches. The hyphen is optional, as is
the plural (inches versus inch).
Filter entrires can be anything, but I prefer the following: B,
V, R, I, C (clear or unfiltered), BB (blue blocking), G (pretty picture
green) and Bp (pretty picture B-band). The BVRI filter designations are
assumed to be "photometric (e.g., B is Johnson B-band, R means Rc or Cousins
R-band, I means Ic or Cousins I-band). don't If you buy a color filter
wheel with filters installed you have to assume that the B filter is not
photometric, but is what I call Bp, or "pretty picture B band." Bp has a
longer wavelength than B. Johnson and Cousins V-band are essentially the
same, so don't worry about which one you're using. Whether your filter conforms
to the Johnson-Cousins standard or not is really unimportant, so it's optional
to distinguish between R and Rc, etc.
Exposure can be simply a number of seconds; it's optional to add
"s" or "sec" or "seconds".
ClockCorrn is the number of seconds that must be added to your
JD time tags, where it is assumed that ClockCorrn seconds will be converted
to "day" units before adding. For example, if your computer clock was fast
(ahead) by 5 seconds you should enter -5 for ClockCorrn. It is a good practice
to synchronize your computer clock with some time standard with an accuracy
better than ~ 10 seconds because the JD time tag is based on it being accurately
set. It's OK to check the clock after an observing session, and then simply
note in the ClkCorrn header line a correction value to be used by my auto-fit
processing program. This is so important that a data file will be rejected
if the ClockCorrn header line is not present. Also, check to make sure the
JD time tags correspond to mid-exposure, not start of exposure. To
do this, display the FITS header for an image and note
the exposure start time. Add 1/2 the exposure time
and calculate JD. Compare this JD with the JD in
the "observations data file" and if they differ, enter
the seconds equivalent in the header. The term "ClkCorrn" can
be used as well as "ClockCorrn" (to remain compatible with an older format).
Loss column (also Loss Column, or LossColumn - recall
that capitalization doesn't matter) should be either Y or N (for Yes or
No) to indicate whether the data section contains "extra losses" as a third
column. In almost all cases the "Loss Column" line will have an "N" entry.
It is present for those rare observers (like myself) who calculate "extra
losses" (due to clouds, dew, seeing degradation, etc) by using an "artificial
star" with MaxIm DL's photometry tool followed by an import of the CSV-file
to a spreadsheet where extra losses are calculated.
Comment information is merely archived, and is not made use of
by my auto-fit processing program. Any number of comment header lines are
acceptable, and it is optional to label them as Comment1, Comment2, etc.
They can all be simply Comment.
Note that all header lines include a colon symbol ":". The colon
can be immediately after the header title (as in "Filter: R") or at the
same column as the other header lines (as in Filter : R").
May I suggest that you create a header text file that can be inserted just
above the data section of files that are recorded by your image analysis program.
After inserting this user-specific header file you can edit it to show the
correct observing date, object, etc using a program such as TotalCommander:
http://www.ghisler.com/ (I
don't know how anybody can use a PC without TotalCommander). A sample header
text file can be downloaded using this link: YMDDabc1.txt.
Filename
Here's an example of my preferred filename convention: 9531GJ2.txt.
It conveys the information that
the observations began on the
date 2009 May 31 (UT) and the observer uses
an observer code of GJ2. If you don't have a 3-letter observer code (assigned
by AAVSO) you may use use the first letter of your last name, the first
letter of your first name, and the number 2. For example, John Doe would
be DJ2.
Sometimes there may be two exoplanet observations on the same date. When
this happens the two filenames can look like this: 9531GJ21.txt and
9531GJ22.txt. This convention allows for up to 9 exoplanet observations
per date.
What do you do for observing dates after Spetember, or Month #9? Computer
programmers are accustomed to "thinking Hex" - which is a 16-based numbering
system that goes from zero to 15 in the following manner: 1, 2, 3, 4, 5,
6, 7, 8, 9, A, B, C, D, E and F. So, using Hex notation, October is "A",
November is "B" and December is "C". Therefore, if your observing date is
December 31, the filename (for observer GJ2) would be 9C31GJ2.txt.
Attach your data file to an e-mail and send it to:
a x a @ b r u c e g a r
y . n e t [remove
spaces between characters]
These format
instructions for submitting data may seem excessive but remember
that if you adhere
to them it will save me time, and I'm
processing your data and maintaining
the AXA archive without pay. Also, when
Caltech takes over the AXA they will require
that you adhere to a format or your submission
will be rejected. I think Caltech is inclined to accept the
format described here.
Data Rejection Criteria
A data file will be rejected by the auto-fit pipeline for
failing to meet any of the following requirements.
1) The data file must include all 5 of the following header lines:
Object, Observer, Latitude, ELongitude and StartDate.
2) The observing session length must exceed 2 hours.
3) The 2-minute equivalent RMS noise must average < 15 mmag.
4) The auto-fit solution search must succeed within 99 iterations.
5) The auto-fit systematic coefficients must be less than 10 mmag/hour
and 15 mmag/air mass.
When an observing session does not include either an ephemeris ingress
or egress, program control is automatically transferred to program "AXA5"
which treats the data as OOT.
____________________________________________________________________
WebMaster: B.
Gary.
Nothing on this
web page is copyrighted. This site opened: 2008 August
23. Last Update: 2009.09.09